



虚拟与现实世界已真假难辨!30多个Open AI视频范例震撼曝光,行业饭碗没了?(组图)
“现实将不存在了”?
刚刚,人工智能AI行业又迎来了疯狂、震撼的一天!
当地时间2月15日,人工智能AI巨头OpenAI宣布,正正式发布其首个文本-视频生成模型Sora,通过简短或详细的提示词描述,或一张静态图片,Sora就能生成类似电影的逼真场景;

涵盖多个角色、不同类型动作和背景细节等,最高能生成1分钟左右的1080P高清视频。
“一名时尚女子走在充满霓虹灯和广告牌的标志性东京街头,她穿着黑色皮夹克、红长裙和黑靴子,拎着黑色手袋,戴着太阳镜,涂着红色口红,走路自信又随意。街道潮湿且反光,在灯光映射下形成镜面效果,行人走来走去。”
60秒的视频,完全是OpenAI的模型Sora用提示指令(Prompt)生成。
更值得注意的是,Sora生成的视频不再具有以往AI生成视频的“间断感”,每一帧之间的过渡非常流畅,仿佛是真实拍摄的一样!
不仅如此,Sora生成的视频中,还包含了多种不同景观的镜头,例如从全景到特写的切换,而且还捕捉到了脸上的痘印等细节,令人惊叹不已。

网友:足以以假乱真!
当然,除了这个1分钟的长镜头,OpenAI还放出了30多个Demo,让我们一起来看看。
“一个20多岁的年轻人坐在云朵上看书”,惟妙惟肖的细节与恰到好处的动感令人惊叹:放在以前,做出来这样的东西可是要花专业特效人员好长时间啊!

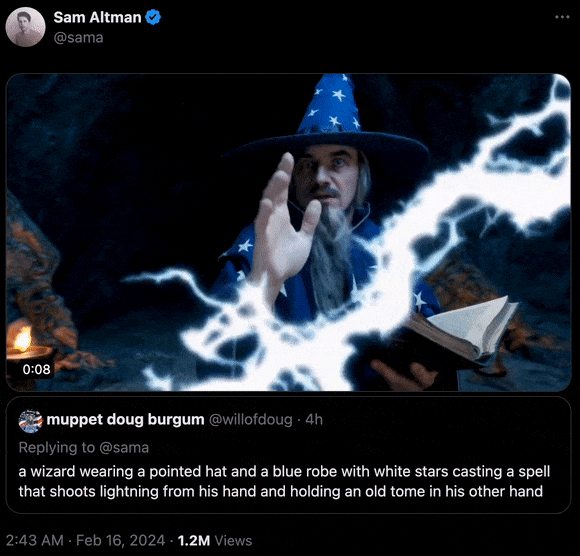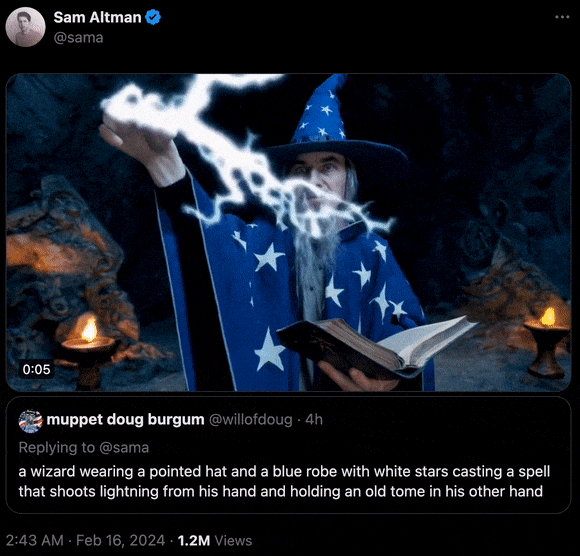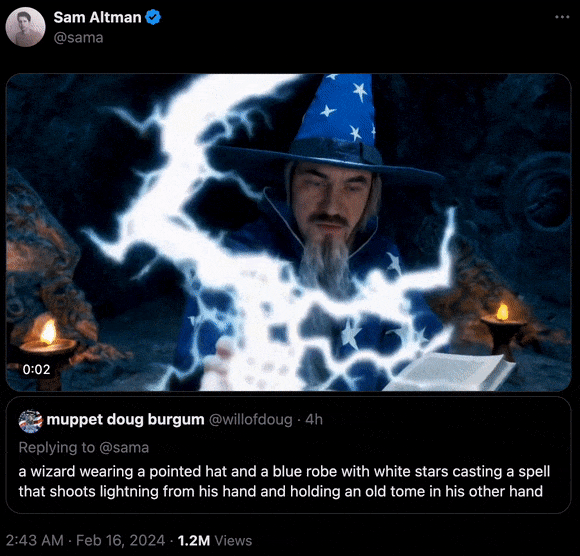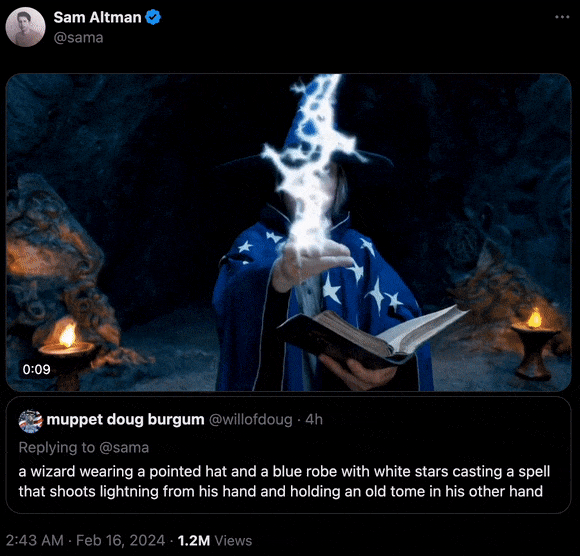
“一位戴着尖帽子、身披带有白色星星的蓝色长袍的巫师正在施法,他一只手发射着闪电,另一只手持一本旧书。”
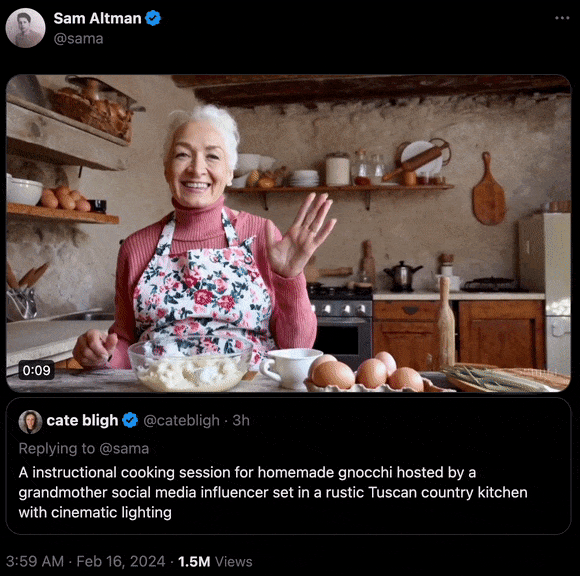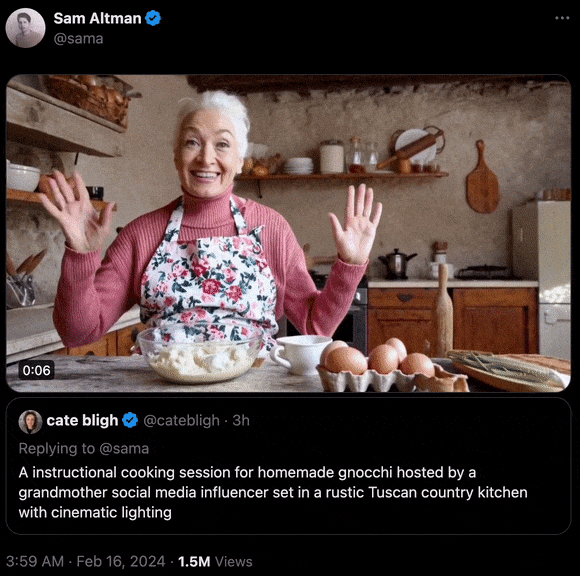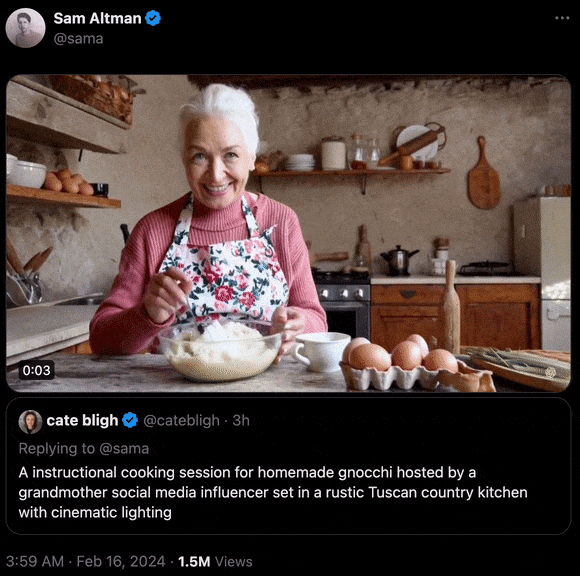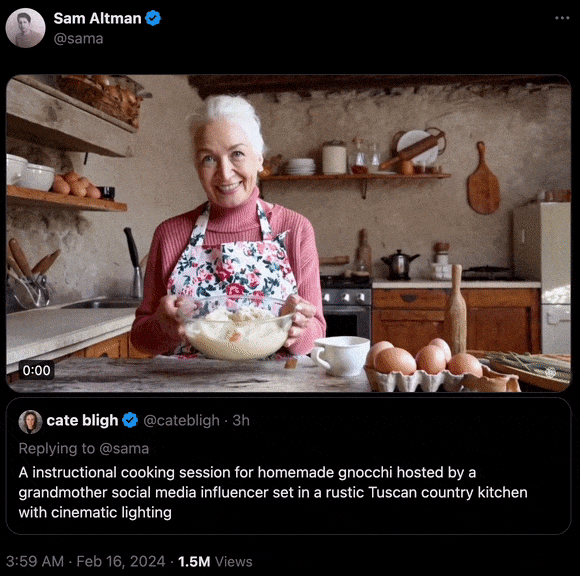
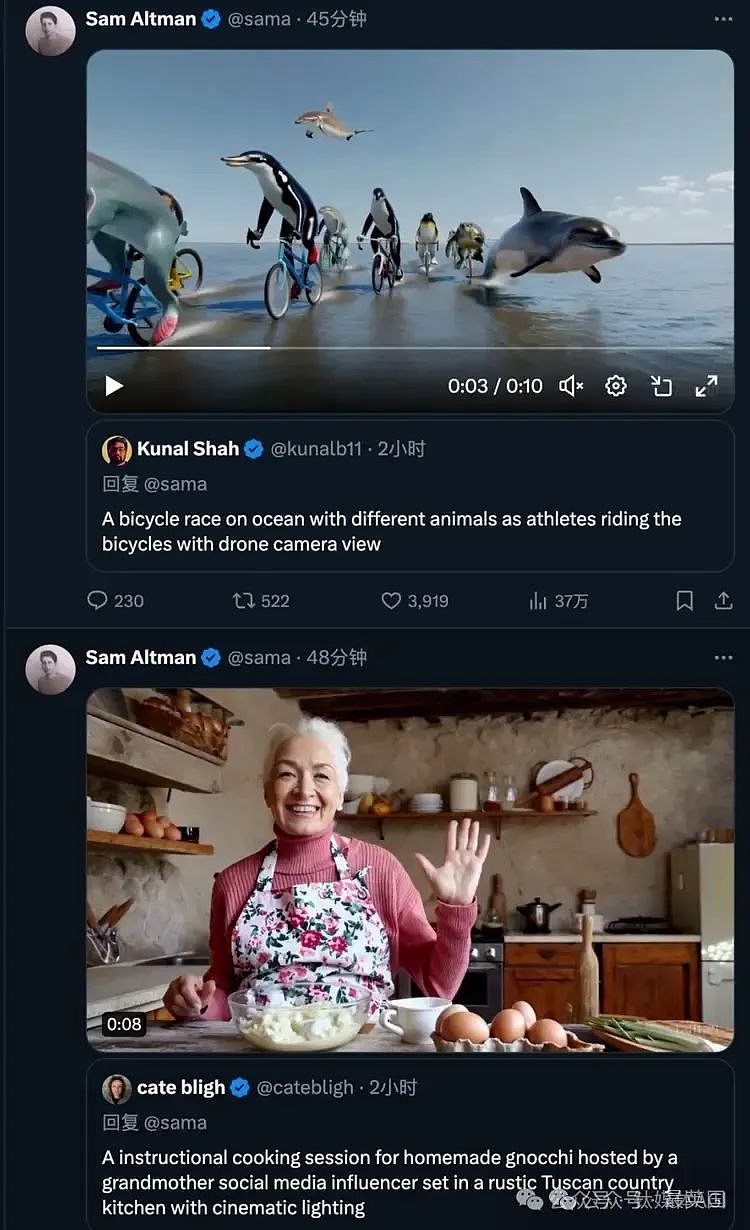
“在一间设有电影级灯光的厨房里,充满了托斯卡纳乡村的风情,一位社交媒体达人奶奶正在教你制作美味的自制诺奇面。”
“一群小熊猫在长出竹子的培养皿中奔跑玩耍”;

“咖啡杯里有两艘海盗船角逐”,内容的细节、画质和连续性都完美;

“跳Disco的袋鼠”

“中国新年龙”

“金毛幼犬被覆盖在雪地里”

可以看出,Sora在语义理解、视频的画风、传递的情感上都能精准拿捏了!
在部分场景中,Sora的效果足以“以假乱真”:
例如一段8秒的东京地铁车厢窗户视频,连制作玻璃反射的倒影画面,都会根据环境的不同实时呈现变化,人物映像也非常逼真,令人拍案叫绝!

实现了哪些突破?
首先,以前的AI视频,都单镜头生成的。Sora实现了这一突破,可以在不同的场景里连续变幻,而且完全没有“油画感”,非常连贯逼真。
比如这个描述指令:“雪后的东京城熙熙攘攘。镜头穿过繁忙城市街道,跟随几个人享受美丽的雪天并在附近的摊位购物。绚丽的樱花花瓣随着雪花随风飘扬。”

Sora生成的视频呈现了所有要素,且镜头一直向前变换,非常生动。
它所生成的复杂场景不仅包括多个角色,还涵盖特定的动作类型,并对对象和背景进行了精准的细节描绘,甚至传达出了唯美和浪漫!
再看个例子:
“一个电影预告片,以一个30岁的太空人穿着红色羊毛编织的摩托车头盔为特色,背景是蔚蓝的天空和盐沙漠,采用电影风格拍摄,使用35毫米胶片,色彩鲜艳。”

“在雪地草原上,几只巨大的羊毛猛犸象缓缓前行,它们长长的毛皮在微风中轻轻飘动。远处是覆盖着雪的树木和雄伟的雪山,午后的阳光穿透薄云,为这个场景增添了一丝温暖的色彩。低角度的拍摄使这些庞大的毛茸茸动物显得格外壮观,景深效果令人陶醉其中。”

看看这张图中人物的眼睛、睫毛、皮肤纹理,哪有人工智能的痕迹?

不得不说,OpenAI这种多镜头一致性的水平,是Gen 2和Pika完全望尘莫及的……
其次,Sora凭借对语言的深入理解,能精准地解读指令中的需求,并将这些元素生动地呈现在现实世界中,甚至让其创造的角色能够传达丰富的情感,具有了人情味!
“用3D动画的形式,展现一只毛茸茸小怪物在正在融化的蜡烛旁”;

Sora对于毛发纹理物理特性的理解,准确得令人震惊。
这让很多人想到皮克斯的《怪兽公司》电影:要知道,当时为了创造出怪物在移动时超级复杂的毛发纹理,皮克斯团队付出了巨大的努力,技术团队甚至连续工作了数月。
而Sora却轻而易举地实现了这一点,关键是没有人教过它啊!
专家表示:“这不是我们事先设计的,而是完全通过观察大量数据自然而然地学会的。”
再来一个:
“一个以珊瑚礁为背景的精美纸艺世界,充满着五彩缤纷的鱼类和海洋生物。”

谁相信这是AI生成的?
项目研究员Bill Peebles表示:“视频中实际上进行了多次镜头切换——这些镜头并非后期编辑合成,而是模型一气呵成地生成的。我们并没有明确要求它这样做,它却能自动完成。”
由此可见,视频和现实之间究竟还存在何种差异?!
Sora另一个厉害的突破,就是“理解了现实世界不同物品之间的物理关系”,比如这个“轮胎扬起了尘土”,正确地出现在汽车后面。

要知道,由于上次谷歌发布Gemini Ultra时用了剪辑功能,受到广大网友的一批评,这次OpenAI特地声明:
所有视频都是由Sora直接生成的,没有任何修改!
根据OpenAI官网,Sora能够生成具有多个角色、特定类型的运动以及主体和背景的准确细节的复杂场景。Sora不仅了解用户在提示中提出的要求,还了解这些东西在物理世界中的存在方式。
大家可能还记得,2023年的2月,Runway发布了文字生成视频模型Gen系列,仅仅过去一年,AI生成视频就已经可以几乎以假乱真,AI接下来还会牛到什么程度?
存在什么缺点?
当然,Sora也存在一些弱点。OpenAI表示,它可能难以准确模拟复杂场景的物理原理;空间和时间上推理上,还有些搞不清楚;可能难以精确描述随着时间推移发生的事件等。
比如“以平面印刷的效果,展示一个跑步的场景”,结果人跑反了;

“考古学家在沙漠中发现了一把普通的塑料椅子,他们小心翼翼地挖掘并除尘”:
此次指令里,椅子并没有被Sora正确理解为一刚性物体,导致物理交互不准确。

科学家表示,目前,Sora仍处于开发中的阶段,它可能存在难以准确模拟复杂场景物理原理的挑战,并且可能无法理解具体实例中的因果关系。
再比如,有可能出现一个人咬了一口饼干、但后来饼干却没有痕迹的情况。
但瑕不掩瑜,Sora不仅能模拟真实世界,而且包括学习了摄影师和导演的表达手法,将 AI 视频惟妙惟肖地展现出来,已经足够炸裂!
行业要变天,现实不存在了?

Sora视频一出,立刻震惊业界。人工智能专家和分析师表示,Sora 视频的长度和质量超出了迄今为止所见的水平。
在社交平台上,已经有一些视觉艺术家、设计师和电影制作人(以及OpenAI员工)获得Sora访问权限。他们开始不断放出新的提示词,OpenAI CEO奥尔特曼开始了“在线接单”模式。
带上提示词@sama,你就有可能收到奥尔特曼“亲自发布”的 AI 视频回复。
消息公布后,网友直呼,工作要丢了,视频素材行业要“RIP”。
所有人都在感叹:行业真的变天了,AI 快要把人类KO了;好莱坞的时代真的要结束了?
美国伊利诺伊大学香槟分校信息科学教授Ted Underwood指出,没想到在两三年内还会有如此持续连贯水平的视频生成技术,OpenAI的视频可能展现了该模型的最佳性能。
多名AI从业者称,从Sora公布的预览视频来看,简直太“疯狂”!
在国外Reditt社区,有个网友提问,今天OpenAI公布的Sora模型是否会成为自动化对于经济影响的里程碑?下面有数百条回复。
有网友称,起初ChatGPT的发布让用户看到了一切皆有可能,而现在人工智能正在不断进步发展,让用户看到了强大的技术能力。
有网友评论称,Sora的出现是一项改变世界的产品,但同时也指出,Sora生成的视频或许让人工智能专家也难以分辨真假,这或许是个棘手的问题。

外媒援引布法罗大学Media Forensic Lab主任Siwei Lyu的话称,
随着像Sora这样的人工智能程序不断出现,除了由图像和音频深度伪造构成的现有挑战之外,视频伪造技术将带来更多挑战。
卡内基国际事务伦理委员会研究AI和监控技术的高级研究员Arthur Holland Michel则表示,当像Sora这样的工具落入那些“确实想利用新技术迭代造成伤害的老谋深算者”手中时,事情会变得更加糟糕:
“每当有功能更强大的新产品发布时,其可能被滥用的方式也会越多。”
不过,AI视频或许能给电影制造带来不少惊喜。

电影导演和视觉特效专家Michael Gracey说,看看仅仅在图像生成的一年里就取得了如此成就;
他预测,不久之后,像Sora这样的人工智能工具将使电影制作者能够仔细控制他们的输出,从头开始制作各种视频。

Gracey认为,以后或许不再需要一个由100-200名艺术家组成的团队来用3年时间完成动画长片,但他也提醒,AI工具是根据现实生活中艺术家的作品进行训练,而不给予他们补偿,这是一个大问题。
“当它剥夺了其他人的创造力、工作、想法和执行力,而不给予他们应有的荣誉和经济报酬时,那就不好了。”

总结来看,2024年开年,AI 大模型技术进展全面加速,视频、图像、文本生成能力比一年前大大增强。
如果说,2023年还是“AI 图文生成元年”的话,今年,OpenAI将推动行业进入”AI视频生成元年”。
如果按照最近估值超过800亿美元的OpenAI公布新产品的速度来计算,GPT-5将很快对外发布。









 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


